Transfer Learning using ConvNets
Aim: To use a pretrained VGG16 model and apply transfer learning on Caltech 256 Datasets
Data: Contains Image Dataset: Caltech 256
Why CNN?: In a densely connected neural network (like the one mentioned in the MNIST Classification problem) every node in layer is connected to every node in adjacant layers. Obviously every connection basically comprise of its weight parameters and bias’s at each layer. This makes a dense NNet very complex to train. In the MNIST Classification case we had 784x100 + 100X10 trainable weights plus biases. Moreover, although it does a good job classification note that it never “uses” information stored in the spatial characteristics of an image. It just treats the input as a numerical vector and tries to fit the corresponding output.
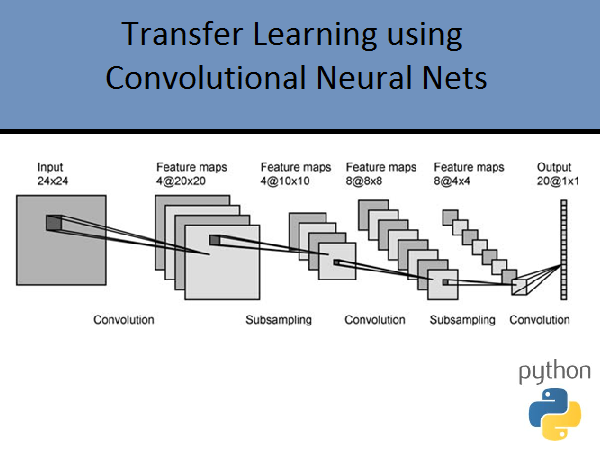
Convolutional Neural Networks (CNN) are very efficient in utilizing the spatial characteristics of an image. The features are build using convoluting standard kernels (which you would use in Image processing) to build features, for example: horizontal gradient, vertical gradient, gaussian kernel, edge detector etc. Now the same kernel traverses along the entire image to build convolution output. Meaning we keep a feature kernel same for the same image for all images. This gives translation invariance to the CNN layer. (If you are detecting a dog in an image, it doesn’t matter where in the image it is located). So say we build 20 such convolution output images which act as your first feature. Thus we reduce the trainable parameters to 3x3 + bias for every feature output. So if we have 20 features 20x3x3 + biases. Thus with the processing power available to us, we can now go build deeper number of layers with CNN model than a dense feed forward network.
Pooling: In order to reduce the output image size we subsample it using Pooling. In max pooling we define a neighborhood (say 3x3) and keep only the max value of pixel in that neighbourhood. This reduces dimensionality by a huge amount.
Final Architecture: We have a number of convolution layers and pooling layers and basically end up with a set of features based on image characteristics not just pixel values. Now we have a final dense layer (softmax) to categorize each training image into its respective class.
Transfer Learning: Training a deep CNN with high accuracy takes a lot of time. But we can use the fact that ultimately CNN is just detecting image characteristics to use a pretrained model. I have used a pretrained CNN model - VGG16 which is trained on for many images belonging to a 1000 classes. This model is available on Keras. The only change made is to replace the softmax layer (1000 classes) with our own (256 classes for Caltech 256). Obviously we will have to retrain this softmax layer to fit our own dataset.
We got a highest train accuracy of 97.75% and test accuracy of 54.88% in the Caltech 256 dataset.
We can actually visualize the filters at the layers to see what characteristics are they exactly detecting. We can also try an suppress the Conv Layers (i.e. connect the softmax layer to some intermediate layer) and observe drop in accuracy